Reinforcement Fine-Tuning sur Amazon Bedrock : comment vos modèles IA apprennent enfin à penser comme votre entreprise
Le fossé entre un modèle d'IA générique et un assistant vraiment utile pour votre secteur d'activité a toujours été le talon d'Achille des projets d'adoption en entreprise. Amazon Web Services vient de franchir une étape décisive avec la disponibilité du Reinforcement Fine-Tuning (RFT) sur Amazon Bedrock, désormais accessible via des APIs compatibles OpenAI. Pour les entreprises françaises qui peinent à transformer leurs expérimentations IA en valeur opérationnelle mesurable, cette évolution mérite une attention particulière.
Du modèle généraliste au spécialiste métier : comprendre le Reinforcement Fine-Tuning
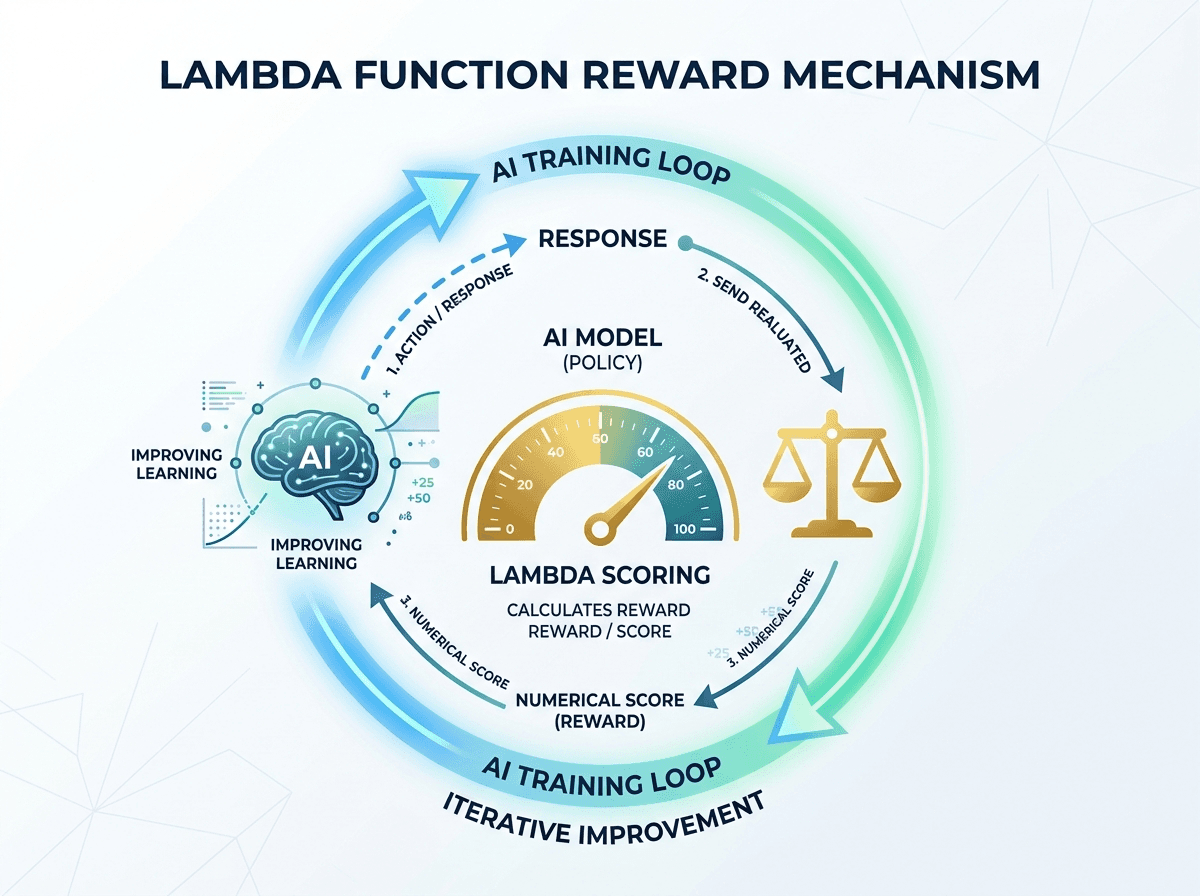
Le fine-tuning classique consiste à montrer des exemples à un modèle pour qu'il imite un comportement souhaité. C'est utile, mais limité : le modèle apprend à reproduire, pas nécessairement à raisonner juste dans votre contexte.
Le Reinforcement Fine-Tuning va beaucoup plus loin. Inspiré des techniques qui ont propulsé des modèles comme o1 d'OpenAI, il s'appuie sur un mécanisme de récompense : le modèle est entraîné à maximiser un score défini par votre entreprise. Concrètement, au lieu de lui dire "voici la bonne réponse, copie-la", vous lui dites "voici comment évaluer si ta réponse est bonne — maintenant apprends à l'optimiser".
Ce qui rend l'implémentation AWS particulièrement accessible, c'est l'architecture proposée :
- Une authentification simplifiée via les mécanismes IAM d'Amazon
- Une fonction AWS Lambda qui héberge votre logique de récompense métier
- Des APIs compatibles OpenAI, ce qui signifie que vos équipes qui connaissent déjà l'écosystème OpenAI peuvent démarrer sans tout réapprendre
- Un déploiement du modèle fine-tuné directement sur Bedrock pour de l'inférence à la demande
Pour une DSI française, cette compatibilité OpenAI est loin d'être anodine : elle réduit drastiquement la dette technique et facilite la portabilité des solutions.
Trois cas d'usage concrets pour les entreprises françaises
La vraie question n'est pas "comment ça fonctionne techniquement" mais "qu'est-ce que ça change pour mon activité". Voici trois scénarios représentatifs du tissu économique français :
1. Cabinet juridique ou d'audit : conformité et précision réglementaire Un modèle généraliste répond correctement en moyenne. Mais dans un contexte de conformité RGPD, de droit du travail français ou de normes IFRS, "en moyenne" ne suffit pas. Avec le RFT, vous pouvez définir une fonction de récompense qui pénalise toute réponse ne citant pas le bon article de loi, ou qui propose une interprétation contraire à la jurisprudence française récente. Votre modèle ne se contente plus de paraître crédible — il est évalué sur la justesse juridique réelle.
2. Industrie manufacturière : analyse de données techniques et maintenance prédictive Un équipementier automobile ou un fabricant aéronautique dispose de données techniques très spécifiques (codes erreurs, nomenclatures propriétaires, historiques de pannes). Un modèle RFT entraîné avec une récompense basée sur la précision du diagnostic — vérifiée par vos experts terrain — devient un assistant de maintenance qui pense comme vos meilleurs techniciens, pas comme une encyclopédie généraliste.
3. Banque et assurance : scoring et argumentation commerciale Les équipes commerciales des institutions financières ont besoin de réponses qui respectent simultanément les contraintes réglementaires (MiFID II, DDA), le positionnement produit et le profil client. Une fonction de récompense multicritères permet d'entraîner un modèle qui optimise ces trois dimensions en même temps — ce qu'aucun prompt engineering, aussi sophistiqué soit-il, ne peut garantir de façon stable.
L'architecture Lambda : votre logique métier au cœur de l'entraînement
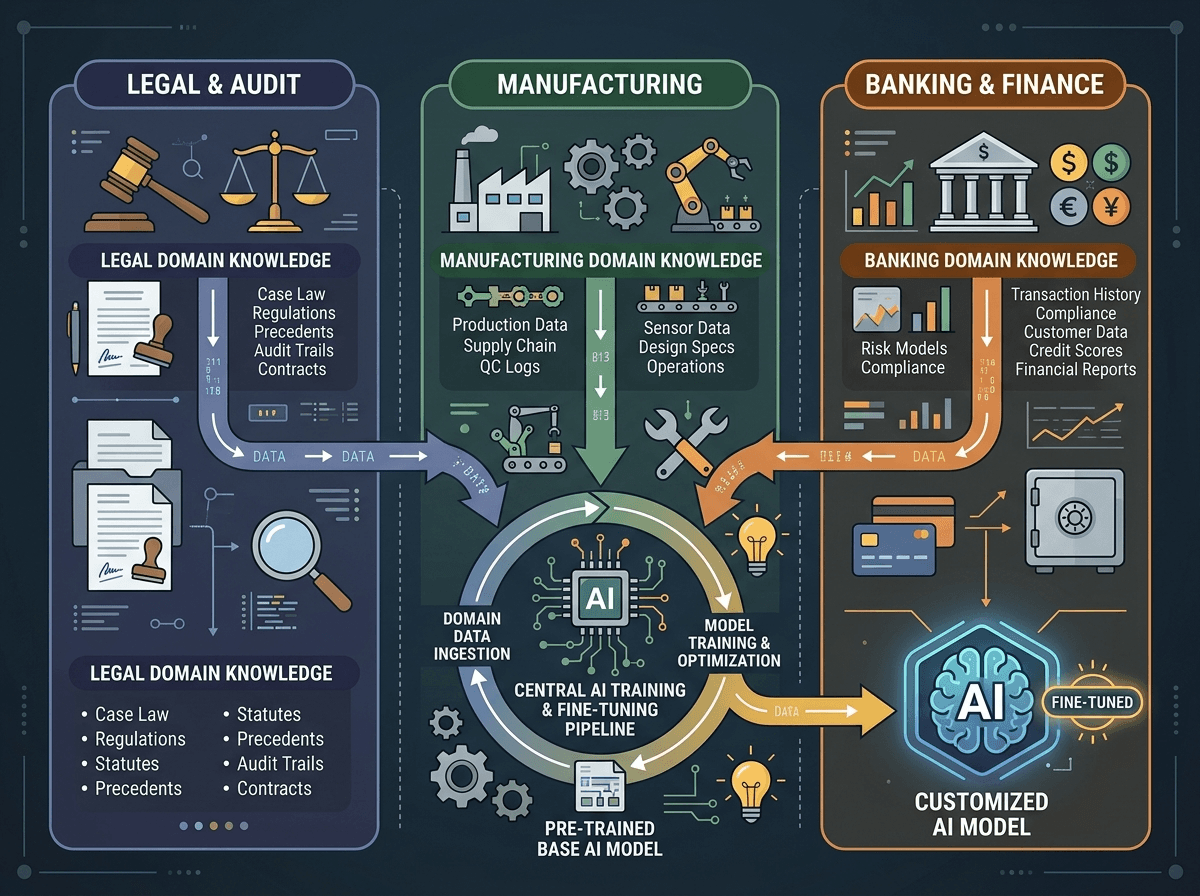
Le choix d'AWS Lambda pour héberger la fonction de récompense est stratégiquement important pour les entreprises françaises, notamment celles soumises à des exigences de souveraineté des données.
Concrètement, votre fonction Lambda reçoit la réponse générée par le modèle en cours d'entraînement, l'évalue selon vos critères propriétaires (qui ne quittent jamais votre environnement AWS), et retourne un score numérique. Ce score guide l'optimisation du modèle.
Les avantages pour une entreprise française sont multiples :
- Souveraineté des critères d'évaluation : votre savoir-faire métier — ce qui fait qu'une réponse est "bonne" dans votre secteur — reste dans votre infrastructure. Il n'est pas exposé à des tiers.
- Auditabilité : la logique de récompense est du code versionnable, testable, documentable. C'est un atout majeur pour les équipes conformité et les auditeurs.
- Évolutivité : quand votre contexte réglementaire change (et en France, il change souvent), vous mettez à jour votre fonction Lambda, et vous pouvez relancer un cycle d'entraînement. Votre modèle évolue avec votre entreprise.
- Coût maîtrisé : Lambda facture à l'usage. Pendant la phase d'entraînement, les coûts d'évaluation sont prévisibles et proportionnels au volume de données.
Le workflow complet — authentification, déploiement Lambda, lancement du job d'entraînement, inférence sur le modèle fine-tuné — est désormais documenté de bout en bout par AWS, ce qui abaisse significativement la barrière à l'entrée pour les équipes techniques françaises.
Former vos équipes : le vrai enjeu de l'adoption
La technologie est là. La vraie difficulté, comme toujours, est humaine. Le Reinforcement Fine-Tuning introduit un paradigme nouveau qui nécessite une montée en compétences sur plusieurs dimensions simultanément.
Vos data scientists doivent comprendre les fondamentaux du reinforcement learning appliqué aux LLMs — notamment les notions de reward shaping, de stabilité d'entraînement et de gestion des biais induits par une mauvaise fonction de récompense. Un modèle mal récompensé peut apprendre à "tricher" : produire des réponses qui scorent bien sans être réellement utiles.
Vos experts métier jouent un rôle nouveau et crucial : ce sont eux qui définissent ce que "bien" signifie. Traduire l'expertise d'un juriste senior ou d'un ingénieur process en critères computationnels est un exercice de co-conception qui demande une nouvelle forme de collaboration entre les équipes techniques et les équipes opérationnelles.
Vos équipes DevOps et cloud doivent maîtriser l'orchestration des services AWS impliqués (IAM, Lambda, Bedrock) et mettre en place les bonnes pratiques de MLOps pour gérer le cycle de vie des modèles fine-tunés en production.
Enfin, vos managers et décideurs doivent intégrer que le fine-tuning n'est pas un projet one-shot mais un processus continu : les modèles doivent être réévalués, ré-entraînés, monitorés. C'est un actif vivant, pas un livrable.
Chez Ikasia, nous accompagnons les entreprises françaises sur l'ensemble de ce spectre — de la formation technique aux ateliers de co-conception des fonctions de récompense avec les experts métier, jusqu'au déploiement en production et à la mise en place de la gouvernance IA.
Le Reinforcement Fine-Tuning sur Amazon Bedrock marque une inflexion réelle dans la maturité des outils IA disponibles pour les entreprises. La question n'est plus de savoir si vos concurrents vont adopter ces technologies, mais à quelle vitesse. Vous souhaitez évaluer la pertinence du RFT pour votre contexte et former vos équipes aux nouvelles pratiques du fine-tuning ? Contactez les experts d'Ikasia pour un diagnostic personnalisé et un programme de formation adapté à votre secteur.
Tags
Formations associées
Articles similaires
Claude d'Anthropic sur Amazon Bedrock en Inde : ce que l'expansion mondiale de l'IA signifie concrètement pour vos équipes françaises
Lire
GPT-5 et Codex sur Amazon Bedrock : ce que les entreprises françaises doivent savoir dès maintenant
Lire
Comment Ring a transformé son support client mondial grâce à l'IA : les leçons pour les entreprises françaises
LireEnvie d'aller plus loin ?
Ikasia propose des formations IA conçues pour les professionnels. De la stratégie aux ateliers techniques pratiques.