Reinforcement Fine-Tuning on Amazon Bedrock: How Your AI Models Finally Learn to Think Like Your Business
The gap between a generic AI model and a truly useful assistant for your industry has always been the Achilles' heel of enterprise AI adoption projects. Amazon Web Services has just taken a decisive step with the availability of Reinforcement Fine-Tuning (RFT) on Amazon Bedrock, now accessible via OpenAI-compatible APIs. For enterprises struggling to transform their AI experiments into measurable operational value, this development deserves particular attention.
From Generalist Model to Domain Specialist: Understanding Reinforcement Fine-Tuning
Classical fine-tuning involves showing examples to a model so it imitates a desired behavior. It's useful, but limited: the model learns to reproduce, not necessarily to reason correctly in your context.
Reinforcement Fine-Tuning goes much further. Inspired by the techniques that propelled models like OpenAI's o1, it relies on a reward mechanism: the model is trained to maximize a score defined by your enterprise. Concretely, instead of telling it "here's the right answer, copy it," you tell it "here's how to evaluate if your answer is good — now learn to optimize it."
What makes AWS's implementation particularly accessible is the proposed architecture:
- Simplified authentication via Amazon's IAM mechanisms
- An AWS Lambda function that hosts your business reward logic
- OpenAI-compatible APIs, meaning teams already familiar with the OpenAI ecosystem can get started without relearning everything
- Deployment of the fine-tuned model directly on Bedrock for on-demand inference
For an enterprise IT director, this OpenAI compatibility is far from trivial: it drastically reduces technical debt and facilitates solution portability.
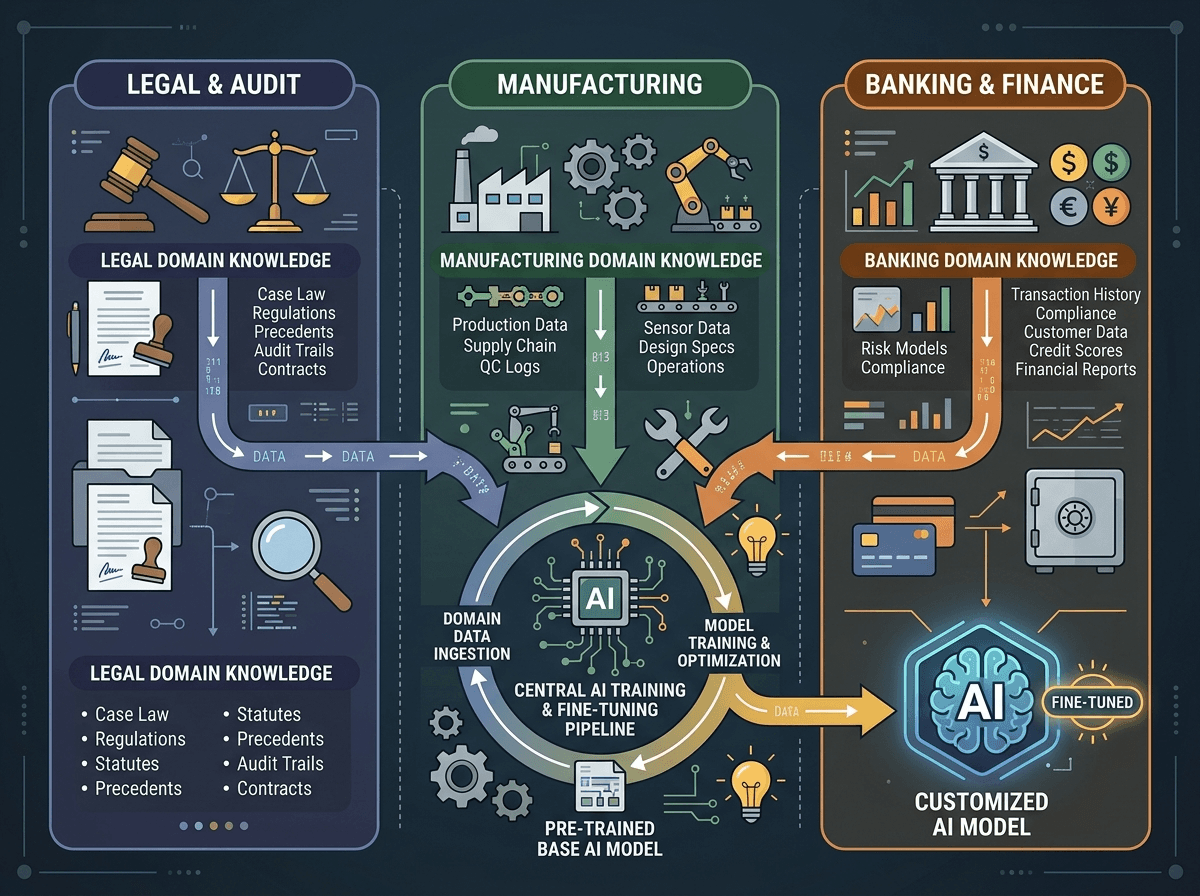
Three Concrete Use Cases for Enterprises
The real question isn't "how does this work technically" but "what does this change for my business." Here are three scenarios representative of the business landscape:
1. Law Firms or Audit Consultancies: Regulatory Compliance and Precision A generalist model answers correctly on average. But in a GDPR compliance, labor law, or IFRS standards context, "on average" isn't enough. With RFT, you can define a reward function that penalizes any response failing to cite the correct legal article or proposing an interpretation contrary to recent case law. Your model doesn't just appear credible — it's evaluated on actual legal accuracy.
2. Manufacturing Industry: Technical Data Analysis and Predictive Maintenance An automotive supplier or aerospace manufacturer has highly specific technical data (error codes, proprietary nomenclatures, failure histories). An RFT model trained with a reward based on diagnostic precision — verified by your field experts — becomes a maintenance assistant that thinks like your best technicians, not like a generalist encyclopedia.
3. Banking and Insurance: Scoring and Commercial Argumentation Commercial teams at financial institutions need answers that simultaneously respect regulatory constraints (MiFID II, DDA), product positioning, and customer profile. A multi-criteria reward function allows you to train a model that optimizes all three dimensions simultaneously — something no prompt engineering, however sophisticated, can guarantee stably.
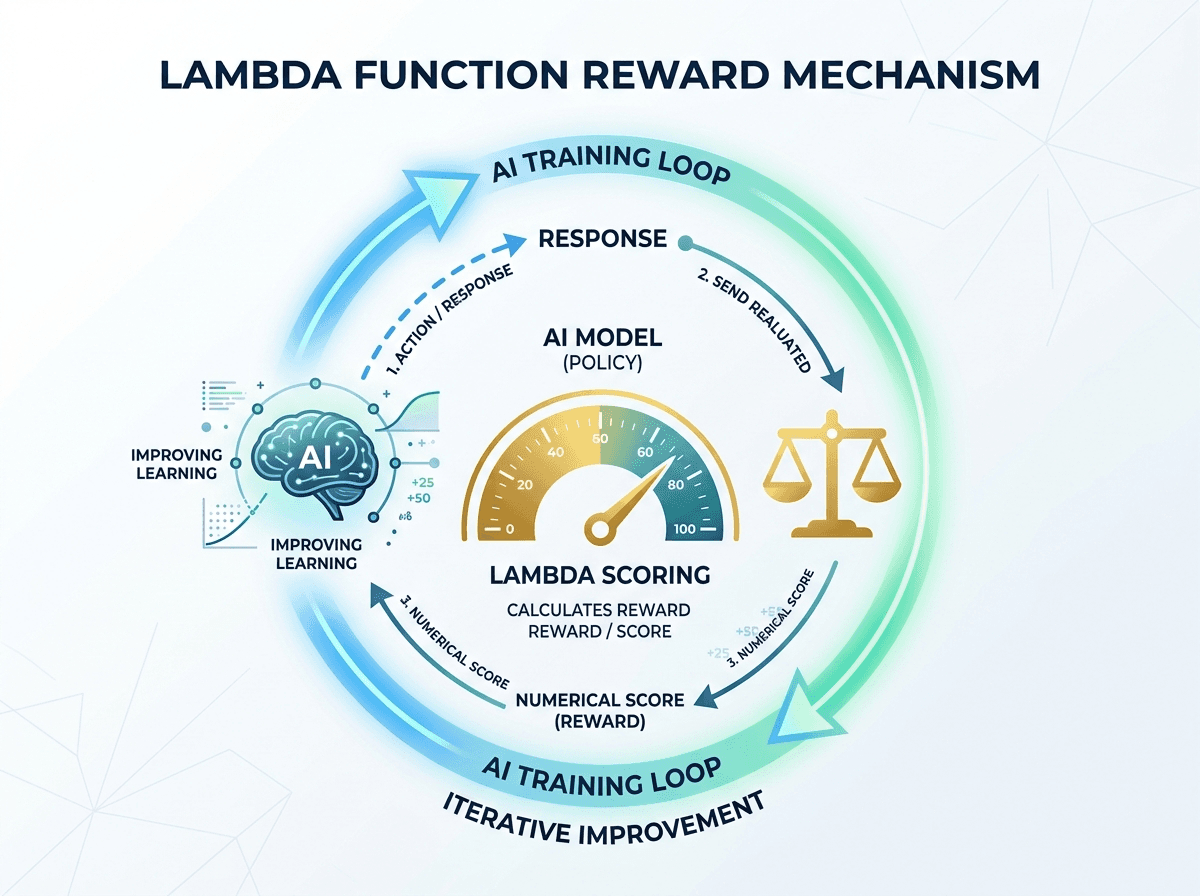
The Lambda Architecture: Your Business Logic at the Heart of Training
AWS's choice of Lambda to host the reward function is strategically important for enterprises, particularly those subject to data sovereignty requirements.
Concretely, your Lambda function receives the response generated by the model during training, evaluates it according to your proprietary criteria (which never leave your AWS environment), and returns a numerical score. This score guides model optimization.
The advantages for an enterprise are multiple:
- Sovereignty of evaluation criteria: your business expertise — what makes an answer "good" in your sector — stays in your infrastructure. It's not exposed to third parties.
- Auditability: the reward logic is versionable, testable, documentable code. This is a major asset for compliance and audit teams.
- Scalability: when your regulatory context changes (and it changes often), you update your Lambda function and can launch a new training cycle. Your model evolves with your enterprise.
- Controlled costs: Lambda charges by usage. During the training phase, evaluation costs are predictable and proportional to data volume.
The complete workflow — authentication, Lambda deployment, training job launch, inference on the fine-tuned model — is now fully documented end-to-end by AWS, which significantly lowers the entry barrier for technical teams.
Training Your Teams: The Real Challenge of Adoption
The technology is there. The real difficulty, as always, is human. Reinforcement Fine-Tuning introduces a new paradigm requiring upskilling across multiple dimensions simultaneously.
Your data scientists must understand the fundamentals of reinforcement learning applied to LLMs — particularly reward shaping, training stability, and managing biases induced by a poorly designed reward function. A poorly rewarded model can learn to "cheat": produce responses that score well without being genuinely useful.
Your domain experts play a new and crucial role: they define what "good" means. Translating the expertise of a senior lawyer or process engineer into computational criteria is a co-design exercise requiring a new form of collaboration between technical and operational teams.
Your DevOps and cloud teams must master the orchestration of involved AWS services (IAM, Lambda, Bedrock) and implement MLOps best practices for managing fine-tuned models' lifecycle in production.
Finally, your managers and decision-makers must understand that fine-tuning isn't a one-shot project but a continuous process: models must be re-evaluated, retrained, monitored. It's a living asset, not a deliverable.
At Ikasia, we support enterprises across this entire spectrum — from technical training to co-design workshops for reward functions with domain experts, through production deployment and AI governance implementation.
Reinforcement Fine-Tuning on Amazon Bedrock marks a real inflection point in the maturity of AI tools available for enterprises. The question is no longer whether your competitors will adopt these technologies, but how quickly. Want to assess the relevance of RFT for your context and train your teams in modern fine-tuning practices? Contact Ikasia experts for a personalized assessment and a training program tailored to your sector.
Tags
Related courses
Related articles

GPT-5 and Codex on Amazon Bedrock: What French Enterprises Need to Know Now
Read
Claude from Anthropic on Amazon Bedrock in India: What Global AI Expansion Means for Your French Teams
Read
How Ring Transformed Global Customer Support with AI: Lessons for French Businesses
ReadWant to go further?
Ikasia offers AI training designed for professionals. From strategy to hands-on technical workshops.